前言
为了应对互联网系统的海量访问,提高系统的qps,目前绝大部分系统都采用了缓存机制,避免数据库有限的IO成为系统瓶颈,极大的提升了用户体验和系统稳定性。虽然使用缓存给系统带来了质的提升,但同时也带来了一些需要注意的问题。本文将讲述缓存常见的问题及解决方案。
缓存穿透
缓存穿透是指访问一个缓存中没有的数据,但是这个数据数据库中也不存在。普通思路下我们没有从数据库中拿到数据是不会触发加缓存操作的。这时如果是有人恶意攻击,大量的访问就会透过缓存直接打到数据库,对后端服务和数据库做成巨大的压力甚至宕机。
解决方案
针对缓存穿透,业界主要有以下两种解决方案:
1、空值缓存
这是一种比较简单的解决方案,在第一次查询的时候,如果缓存未命中,并且从数据库的也查不到数据,就将该Key和null值缓存起来,并且设置一个较短的过期时间,例如5分钟。这样就可以应对短时间内利用同一Key值进行的攻击。
2、Bloom Filter(布隆过滤器)
Bloom Filter是空间效率高的概率型数据结构,用来检查一个元素是否在一个集合中。虽然其他数据结构例如Set和HashMap同样能够检查元素的存在性,但是Bloom Filter极高的空间利用率是其他结构不可比拟的,因此也特别适用于海量数据的建索。它的核心就是一个Bit Array和k个独立的哈希函数。
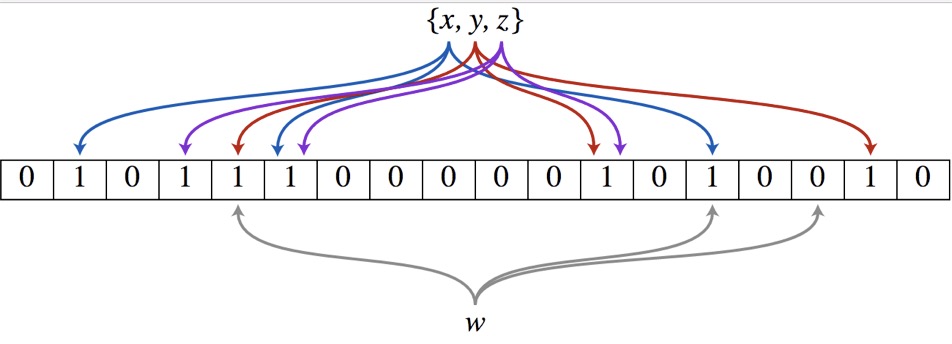
- 添加元素的时候,通过k个哈希函数找到对应于Bit Array上的k个位置,并将这k个位置置1;
- 查询的时候,将要查询的元素进行k个哈希函数计算,找到Bit Array上的k个位置,如果这个k个位置都为1,说明该元素可能存在,否则一定不存在。注意,这里只能说明可能存在,而是存在一定的误判率。这是由于这k个为值1的位置,有可能是其他几个元素计算后的值。误判率是Bloom Filter的一个缺陷。
这里再回到缓存穿透的解决上,我们可以将Bloom Filter放到缓存之前。在查询元素的时候,先通过Bloom filter判断元素是否存在,进而再决定是否请求缓存。
上述两种解决方案都有各自的使用场景:空值缓存可以很好的应对同一Key值的攻击,并且代码维护简单,但是如果攻击的Key值每次都不同,那么缓存中就会出现造成大量无用的空值缓存,并且由于每次攻击的Key不同,还是会穿透到数据库,起不到保护数据库的作用。而Bloom Filter则可以很好应对多个Key值的攻击。
缓存雪崩
由于缓存层承载着大量请求,有效的保护了存储层,但是如果缓存层由于某些原因整体不能提供服务,于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。 缓存雪崩的英文原意是stampeding herd(奔逃的野牛),指的是缓存层宕掉后,流量会像奔逃的野牛一样,打向后端存储。
造成缓存雪崩的原因通常有两个:
- 缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,造成了缓存雪崩。
- 缓存服务发生故障挂了而不响应或者由于网络故障等原因连接超时了,造成所有的查询都落到数据库上
解决方案
1、加锁排队
缓存在集中失效后,将对应Key的缓存更新任务放入队列,并对Key值加分布式锁。这时候由一个线程负责监听更新队列,并逐一取出任务进行缓存更新。等待缓存更新后,解锁Key值。大量访问请求需要排队等待Key值解锁,获取更新后的缓存。这种方式可以避免大量请求到数据库,但是缺点也很明显。由于等待锁期间会有大量线程阻塞,因此也极大降低了系统的QPS。
2、交错失效时间
这种方法比较简单粗暴,既然在同一时间失效会造成请求过多雪崩,那我们错开不同的失效时间,让缓存失效均匀点,即可从一定程度上避免这种问题。在缓存进行失效时间设置的时候,从某个适当的值域中随机一个时间作为失效时间即可。
3、二级缓存
做二级缓存策略,L1为一级缓存,为本地缓存,这里推荐用Caffeine实现;L2为二级缓存,为缓存服务缓存。L1缓存失效时间设置为短期,L2设置失效时间较长于L1。这时候当L1失效时,可以访问L2。这样,通过二级缓存这样就可以避免一部分缓存雪崩的情况。但是,二级缓存的维护难度较大,需要设计好更新策略,提高数据一致性。
4、缓存服务高可用
将缓存服务设计成高可用的,保证在个别节点、个别机器、甚至是机房宕掉的情况下,依然可以提供服务。目前Redis的哨兵模式以及Redis集群都能够实现高可用
5、服务降级
如果在高可用的情况下,缓存服务还是无情的挂掉了,这时候可以通过服务熔断和降级技术,返回预设值,阻止大量请求到数据库。这里推荐使用Hytrix。
缓存击穿
缓存击穿是指由于某个缓存Key的失效,造成大量并发请求直接到数据库,造成数据库的压力。缓存击穿是针对热点Key的,只有热点Key才能在同一时间造成大量并发访问。它与缓存雪崩的区别是,缓存击穿是针对单个热点Key来说,而缓存雪崩是针对大量Key的失效。
解决方案:
1、加分布式锁
加载数据的时候可以利用分布式锁锁住这个数据的Key,对于获取到这个锁的线程,查询数据库更新缓存,其他线程采取重试策略,这样数据库不会同时受到很多线程访问同一条数据。这种方式能够保证缓存重建过程中数据的一致性,但会造成大量线程阻塞,影响系统QPS,对于并发不大的系统来说可以采用。
2、永不过期
从缓存层面来看,不设置过期时间,所以不会出现热点key过期后产生的问题,也就是“物理”不过期。从功能层面来看,为每个value设置一个逻辑过期时间,当发现超过逻辑过期时间后,对Key加更新锁,并使用单独的线程去构建缓存。
3、二级缓存
由于缓存击穿可以看作特殊的缓存雪崩,因此二级缓存机制同样能够解决部分缓存击穿问题。
参考资料:
https://juejin.im/post/5aa8d3d9f265da2392360a37
https://blog.csdn.net/bitcarmanlee/article/details/78635217
https://juejin.im/post/5b849878e51d4538c77a974a